Ну вот нейросети добрались наконец и до аудиозаписей. Появился сервис Adobe Podcast с функцией Enhance speech.
Эта нейросеть от Adobe может улучшить запись с диктофона и приблизить ее по звучанию к дикторской версии, записанной в студии. Нам при этом ничего делать не нужно, нейросеть всё сделает сама.
Для работы с сервисом надо зайти в аккаунт Adobe или зарегистрироваться, если его пока нет. Для этого нажимаем «Sign up». Вход для зарегистрированных — «Sign in».
Вписываем в форму регистрации адрес электронной почты, приджумываем сложный пароль с цифрами и буквами — строчными и прописными. Нажимаем «Continue».
Можно зарегистрироваться с помощью аккаунтов Google или Apple.
Дальше указываем имя, фамилию и дату рождения (месяц и год). Нажимаем «Done».
Дальше придётся подтверждать, что мы не робот. Нажимаем «Start puzzle».
Нужно правильно решить четыре примерно одинаковых задачки. Нужно, чтобы на левой и на правой картинках были одинаковые фигурки в указанном количестве (в моём случае — одна).
Собираем этот пазл, «перебирая» карточки справа с помощью стрелок. Если пара собрана верно. Нажимаем «Submit».
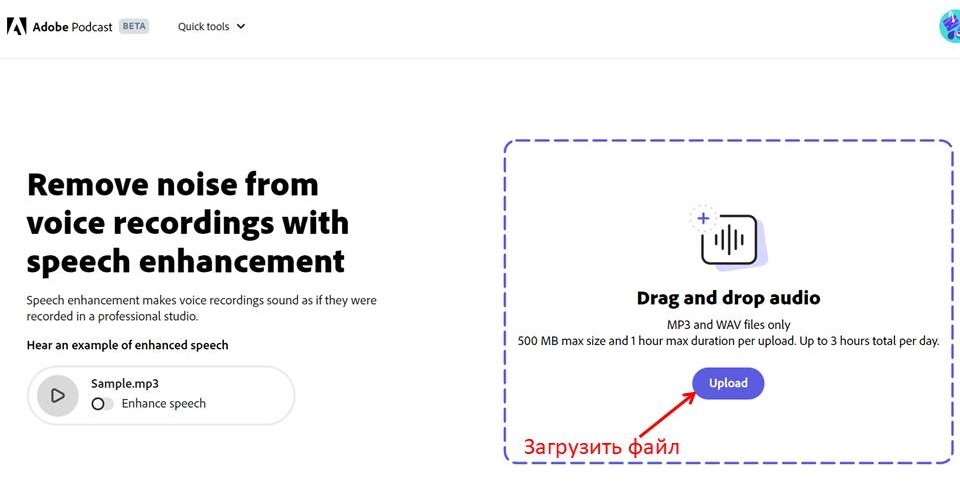
Если все четыре задачки решены верно, нас допустят в личный кабинет. Здесь уже можно загрузить исходный файл с шумами и дефектами, который мы хотим улучшить.
Допускаются файлы в форматах МР3 или WAV, весом не более 500 Mb, продолжительностью до одного часа. Для загрузки нажимаем «Upload».
Ждём, когда нейросеть закончит обработку… Это может занять до 10 минут.
После обработки можно скачать полученный файл на ПК, нажав на кнопку «Download».
Чтобы отредактировать новую аудиозапись, нажимаем «Upload another».
В день с помощью нейросети можно обрабатывать не более трёх часов звукозаписей.
Давайте теперь сравнивать. Это запись до обработки.